

Photo by Hitesh Choudhary on Unsplash
The Most Popular Python Packages: A Comprehensive Guide to Boost Your Development


Introduction:
Python is a powerful programming language known for its simplicity, versatility, and vast ecosystem of libraries and packages. These packages extend the functionality of Python, allowing developers to build complex applications efficiently. In this comprehensive guide, we will explore the most popular Python packages that have gained significant traction in the developer community. From data analysis to web development and machine learning, these packages cover a wide range of domains and can greatly enhance your development process. So, let's dive in and discover the gems of the Python package ecosystem.
NumPy
Introduction:
NumPy is a fundamental package for scientific computing in Python. It provides powerful array objects and a collection of mathematical functions that enable efficient numerical operations. Whether you are working with large datasets, performing complex calculations, or implementing machine learning algorithms, understanding NumPy is essential. In this in-depth exploration, we will delve into the features, capabilities, and best practices of NumPy, empowering you to leverage this powerful library for your data analysis and scientific computing needs.
- Understanding NumPy's Array Object
NumPy's array object, ndarray, is at the core of its functionality. In this section, we will cover the following topics:
Creating NumPy arrays: Explore various methods to create arrays, including array constructors, conversion from other data structures, and using built-in functions like linspace and arrange.
Array attributes: Learn about the essential attributes of NumPy arrays, such as shape, size, and data type. Understand how to access and modify these attributes.
Array indexing and slicing: Discover different indexing techniques, including integer indexing, boolean indexing, and slicing. Understand how to extract specific elements or subsets of an array efficiently.
Array operations: Explore element-wise operations, broadcasting, and vectorized computations. Learn how to perform mathematical operations, apply functions, and manipulate arrays efficiently.
- Working with Multidimensional Arrays
NumPy excels at handling multidimensional arrays, enabling efficient processing of complex data structures. In this section, we will cover the following topics:
Multidimensional array creation: Learn how to create and initialize multidimensional arrays, including matrices, tensors, and higher-dimensional arrays.
Array reshaping and resizing: Understand how to reshape and resize arrays, converting between different dimensions and sizes.
Array manipulation: Explore techniques for array stacking, splitting, transposing, and concatenating. Learn how to change the structure and arrangement of elements within an array.
Broadcasting and vectorization: Gain a deep understanding of NumPy's broadcasting rules and how they enable efficient element-wise operations on arrays with different shapes.
- Mathematical Operations and Linear Algebra with NumPy:
NumPy provides an extensive collection of mathematical functions and tools for linear algebra. In this section, we will cover the following topics:
Mathematical functions: Discover NumPy's mathematical functions, including trigonometric, exponential, logarithmic, statistical, and special functions. Learn how to apply these functions to arrays efficiently.
Linear algebra operations: Understand NumPy's linear algebra capabilities, such as matrix multiplication, solving linear equations, computing eigenvalues and eigenvectors, and performing matrix factorizations.
Random number generation: Explore NumPy's random module, which offers functions to generate random numbers and arrays following different probability distributions.
- Data Manipulation and Filtering :
NumPy provides powerful tools for data manipulation and filtering. In this section, we will cover the following topics:
Array sorting and searching: Learn how to sort arrays, search for specific elements, and find indices based on conditions.
Array filtering: Understand how to apply boolean masks to arrays, filtering elements based on specific criteria.
Array aggregation: Explore techniques for aggregating array data, including summing, finding the minimum and maximum values, and calculating statistics like mean and variance.
- Performance Optimization and Best Practices :
To utilize NumPy efficiently, it's crucial to understand performance optimization techniques and best practices. In this section, we will cover the following topics:
Vectorization: Discover the benefits of vectorized operations and how they can significantly improve code performance.
Memory management: Understand NumPy's memory layout and how to
optimize memory usage for large arrays.
Universal functions (ufuncs): Learn about NumPy's ufuncs, which provide fast, element-wise operations on arrays.
Broadcasting best practices: Explore guidelines for using broadcasting effectively and avoiding common pitfalls.
Conclusion:
NumPy is an indispensable library for numerical computing in Python. With its powerful array of objects, mathematical functions, and efficient computations, NumPy empowers developers and data scientists to tackle complex numerical tasks effectively. By mastering the concepts, techniques, and best practices covered in this in-depth exploration, you will be equipped with the knowledge and skills to leverage NumPy for various scientific computing applications, data analysis, and machine learning projects. Embrace the power of NumPy and unlock a world of possibilities in your Python programming journey.
Pandas

Pandas is a Python library that provides high-performance, easy-to-use data structures and data analysis tools for working with structured (tabular, multidimensional, potentially heterogeneous) and time series data. It aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open-source data analysis/manipulation tool available in any language. It is already well on its way towards this goal.
Pandas is built on top of the NumPy library, which provides fast N-dimensional array manipulation. It also uses the IPython/Jupyter Notebook, which provides a powerful interactive environment for developing and testing code.
Pandas provides several data structures for working with structured data, including:
DataFrames: DataFrames are tabular data structures that can be used to store and manipulate data in a variety of formats. They are similar to spreadsheets, but they are much more powerful and flexible.
Series: Series is one-dimensional data structures that can be used to store and manipulate data of a single type. They are similar to vectors, but they are much more powerful and flexible.
Panels: Panels are three-dimensional data structures that can be used to store and manipulate data in a variety of formats. They are similar to cubes, but they are much more powerful and flexible.
Pandas also provides several data analysis tools for working with structured data, including:
Data cleaning: Pandas provides several tools for cleaning and transforming data. This includes tools for removing duplicates, filling in missing values, and converting data types.
Data analysis: Pandas provides several tools for analyzing data. This includes tools for summarizing data, performing statistical tests, and creating visualizations.
Data visualization: Pandas provides several tools for visualizing data. This includes tools for creating bar charts, line charts, and scatter plots.
Pandas is a powerful and versatile library for working with structured data. It is easy to learn and use, and it provides a wide range of features for data cleaning, analysis, and visualization.
Here are some of the benefits of using Pandas:
Powerful: Pandas is a very powerful library that can be used to perform a wide range of data analysis tasks.
Easy to use: Pandas are relatively easy to learn and use, even for beginners.
Flexible: Pandas is a very flexible library that can be used to work with a wide variety of data formats.
Community: Pandas has a large and active community of users and developers who can provide support and help with troubleshooting.
If you are working with structured data, Pandas is a great library to consider using. It is powerful, easy to use, flexible, and has a large and active community of users and developers.
Here are some examples of how Pandas can be used:
Data cleaning: Pandas can be used to clean and transform data. This includes tools for removing duplicates, filling in missing values, and converting data types.
Data analysis: Pandas can be used to analyze data. This includes tools for summarizing data, performing statistical tests, and creating visualizations.
Data visualization: Pandas can be used to visualize data. This includes tools for creating bar charts, line charts, and scatter plots.
Here are some resources for learning more about Pandas:
Official documentation: The official Pandas documentation is a great resource for learning about the library.
Tutorials: There are many tutorials available online that can help you get started with Pandas.
Books: There are several books available that can teach you how to use Pandas.
Community: The Pandas community is very active and there are many resources available online for help and support.
Matplotlib
Matplotlib is a Python library for creating static, animated, and interactive visualizations. It is a popular choice for data visualization in Python, and it is used by a wide range of industries, including science, engineering, and business.
Matplotlib is a powerful library, but it can be difficult to learn. This article will provide a brief overview of Matplotlib, and it will show you how to create some basic visualizations.
Getting started with Matplotlib
To get started with Matplotlib, you will need to install it. You can do this using the pip package manager:
Code snippet
pip install matplotlib
Once you have installed Matplotlib, you can import it into your Python code:
Code snippet
import matplotlib.pyplot as plt
Creating a simple plot
The most basic type of plot that you can create with Matplotlib is a line plot. To create a line plot, you will need to create a list of x-values and a list of y-values. You can then use the plt. plot() function to plot the points.
The following code creates a line plot with x-values from 0 to 10 and y-values from 0 to 100:
Code snippet
x = range(10)
y = range(100)
plt.plot(x, y)
This code will create a line plot with 10 points. The x-values will range from 0 to 9, and the y-values will range from 0 to 99.
Customizing your plots
Matplotlib provides a wide range of options for customizing your plots. You can change the colours, line styles, and labels of your plots. You can also add titles, legends, and annotations to your plots.
The following code shows how to customize a line plot:
Code snippet
x = range(10)
y = range(100)
plt.plot(x, y, color='red', linestyle='dashed', label='My plot')
plt.title('My title')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.legend()
plt.show()
This code will create a line plot with the same data as the previous example. However, the line will be red, dashed, and labelled "My plot." The plot will also have a title, an x-axis label, and a y-axis label.
Saving your plots
Once you have created a plot, you can save it to a file. To do this, you can use the plt. savefig() function. The following code saves the plot from the previous example to a file named "my_plot.png":
Code snippet
plt.savefig('my_plot.png')
Conclusion
Matplotlib is a powerful Python library for creating static, animated, and interactive visualizations. It is a popular choice for data visualization in Python, and it is used by a wide range of industries, including science, engineering, and business.
This article has provided a brief overview of Matplotlib, and it has shown you how to create some basic visualizations. For more information, please refer to the matplotlib documentation.
TensorFlow

TensorFlow is a popular open-source machine learning framework developed by Google. It offers a flexible and efficient ecosystem for building and deploying machine learning models, including deep learning algorithms. TensorFlow's extensive collection of tools, libraries, and pre-trained models makes it a top choice for researchers and practitioners in the field of artificial intelligence.
Scikit-learn
Scikit-learn, often abbreviated as sklearn, is a powerful open-source machine learning library for Python. With its extensive range of algorithms and tools, Scikit-learn simplifies the process of implementing machine learning models and performing various tasks such as classification, regression, clustering, and dimensionality reduction. In this comprehensive guide, we will explore the key features and functionalities of Scikit-learn, along with practical examples to help you harness the full potential of this library in your machine learning projects.
- Installation and Setup
Before diving into Scikit-learn, let's ensure that you have it installed on your system. We will guide you through the installation process, including the necessary dependencies, and set up a Python environment to work with Scikit-learn effectively.
- Getting Started with Scikit-learn
In this section, we will provide an overview of Scikit-learn and its core concepts. You will learn about the essential components of Scikit-learn, such as data representation, model selection, evaluation metrics, and the general workflow for building machine learning models.
- Data Preprocessing
Before feeding data to machine learning algorithms, it's crucial to preprocess and transform the data appropriately. This section will cover various preprocessing techniques, including handling missing data, feature scaling, encoding categorical variables, and splitting data into training and testing sets.
- Supervised Learning Algorithms
Scikit-learn offers a wide range of supervised learning algorithms. In this section, we will explore popular algorithms such as linear regression, logistic regression, decision trees, random forests, support vector machines (SVM), and k-nearest neighbors (KNN). We will discuss the theoretical foundations of each algorithm and provide practical examples for implementation and evaluation.
- Unsupervised Learning Algorithms
Unsupervised learning allows you to discover patterns and structures in data without explicit labels. We will dive into unsupervised learning algorithms provided by Scikit-learn, including k-means clustering, hierarchical clustering, principal component analysis (PCA), and t-distributed stochastic neighbor embedding (t-SNE). We will discuss their applications, use cases, and implementation details.
- Model Evaluation and Validation
Evaluating and validating machine learning models is essential to ensure their performance and generalization. In this section, we will cover techniques for assessing model performance, including accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). We will also discuss cross-validation, hyperparameter tuning, and model selection strategies to enhance model performance.
- Pipelines and Feature Selection
Scikit-learn provides powerful tools for building machine learning pipelines, allowing you to chain multiple data preprocessing steps and models together. We will explore how to construct pipelines efficiently and use feature selection techniques to improve model performance and reduce overfitting.
- Working with Text Data
Text data presents unique challenges in machine learning. We will explore techniques for preprocessing and vectorizing text data, including tokenization, stop-word removal, and TF-IDF (Term Frequency-Inverse Document Frequency) vectorization. We will also discuss how to apply machine learning algorithms to text classification tasks.
- Ensemble Methods and Model Stacking
Ensemble methods combine multiple models to achieve better predictive performance. We will explore popular ensemble techniques such as bagging, boosting, and stacking. We will discuss how to implement ensemble methods in Scikit-learn and leverage the strengths of different models to improve overall performance.
- Deploying Machine Learning Models
Once you have built and trained your machine learning model, it's time to deploy it into production. We will discuss different deployment strategies, including exporting models, creating APIs, and deploying models on cloud platforms.
Conclusion:
Scikit-learn is a comprehensive and versatile machine-learning library that empowers Python developers to build powerful and accurate models efficiently. In this guide, we covered the installation and setup of Scikit-learn, its core concepts, and explored various supervised and unsupervised learning algorithms. We also discussed model evaluation, pipelines, text data processing, ensemble methods, and deployment strategies.
By mastering Scikit-learn, you will gain the skills and knowledge necessary to tackle real-world machine-learning problems. So, dive into Scikit-learn, experiment with its capabilities, and unleash the potential of machine learning in your projects. Happy learning and exploring!
Django

Django is a high-level, open-source Python web framework known for its simplicity, robustness, and scalability. It provides a solid foundation for building web applications quickly and efficiently. With its batteries-included approach, Django offers a comprehensive set of tools and features that simplify the development process, allowing developers to focus on writing clean and maintainable code. In this comprehensive guide, we will explore the key features, components, and best practices of Django Python, empowering you to develop robust and professional web applications.
- Getting Started with Django
Installation: Learn how to install Django and set up a development environment on your system.
Project Structure: Understand the structure of a Django project and its components.
Creating a Django Project: Step-by-step instructions on creating your first Django project.
- Models and Databases
Object-Relational Mapping (ORM): Discover Django's powerful ORM that allows you to interact with databases using Python code.
Models: Learn how to define models and their relationships, and explore common field types.
Migrations: Understand the concept of database migrations and how to apply and manage them.
Querying the Database: Perform CRUD (Create, Read, Update, Delete) operations using Django's ORM.
- Views and Templates
Views: Learn how to handle HTTP requests and define views in Django.
URL Routing: Understand how to map URLs to views using Django's URL routing system.
Templates: Explore Django's template system and learn how to render dynamic content in HTML templates.
- Forms and Authentication
Forms: Create and handle HTML forms using Django's Form class and form validation.
User Authentication: Implement user authentication and authorization in Django using built-in functionalities.
Authentication Middleware: Secure your web application by implementing authentication middleware.
- Admin Interface
Django Admin: Discover Django's built-in admin interface for managing data and performing administrative tasks.
Customizing the Admin: Learn how to customize the admin interface to match your application's requirements.
- Working with Static and Media Files
Static Files: Handle static files such as CSS, JavaScript, and images in Django.
Media Files: Learn how to handle user-uploaded files and serve them through your application.
- Django Forms and Class-Based Views
Django Forms: Dive deeper into Django forms and explore form validation, formsets, and form rendering.
Class-Based Views: Understand the concept of class-based views and how to use them in Django.
- Testing and Debugging
Unit Testing: Write test cases to ensure the correctness of your Django application.
Debugging: Learn debugging techniques and tools to identify and fix issues in your code.
- Django Rest Framework
Building APIs: Explore Django Rest Framework (DRF) for building robust and scalable APIs.
Serializers: Understand how serializers work in DRF to convert complex data types into JSON.
Authentication and Permissions: Implement authentication and permissions for your API endpoints.
- Deployment and Scaling
Deployment Options: Explore different options for deploying Django applications, including platforms like Heroku and AWS.
Scaling Django: Learn techniques for scaling your Django application to handle high traffic and optimize performance.
Conclusion:
Django Python provides developers with a powerful and efficient framework for building web applications. Its emphasis on simplicity, scalability, and best practices makes it an excellent choice for projects of all sizes. By following this comprehensive guide, you have gained a solid understanding of Django's key features, including models and
databases, views and templates, forms and authentication, the admin interface, testing and debugging, and API development.
As you continue your journey with Django, remember to explore the official Django documentation, participate in the vibrant Django community, and continue building projects to apply your knowledge. With Django's versatility and your newfound skills, you are well-equipped to develop professional, robust, and scalable web applications. Happy coding with Django!
Flask
Flask is a lightweight and versatile Python web framework that simplifies the process of building web applications. It provides a minimalistic yet powerful foundation for developers to create robust and scalable web solutions. Flask follows the principle of simplicity and focuses on giving developers the freedom to choose their tools and libraries while providing essential features for web development. In this comprehensive guide, we will explore the key features, components, and best practices of Flask to help you get started on your journey of building web applications with Python.
- Setting Up a Flask Projects :
To begin with Flask, you need to set up a project environment. This involves installing Flask, creating a virtual environment, and configuring your project structure. We'll guide you through the process step by step, ensuring you have a solid foundation for your Flask project.
- Handling Routes and Requests :
Flask follows the principle of the Model-View-Controller (MVC) architectural pattern, allowing you to map URLs to specific functions or methods called views. We'll explore how to define routes and handle different types of HTTP requests, such as GET and POST. Additionally, we'll cover dynamic routing, route parameters, and URL building.
- Rendering Templates :
Flask incorporates a powerful templating engine called Jinja2, which allows you to separate your application logic from the presentation layer. We'll explain how to use templates to dynamically generate HTML pages, pass data to templates, and create reusable components. You'll learn about template inheritance, control structures, and filters to enhance your application's user interface.
- Working with Forms :
Forms play a crucial role in web applications, enabling users to interact with your application and submit data. Flask provides convenient tools for handling form submissions, validating user input, and displaying error messages. We'll guide you through the process of building and processing forms using Flask-WTF, a Flask extension for working with forms.
- Database Integration :
Most web applications require persistent data storage. Flask integrates seamlessly with various database systems, including SQL databases like SQLite, MySQL, and PostgreSQL. We'll explore how to set up database connections, create models using Flask-SQLAlchemy, perform CRUD (Create, Read, Update, Delete) operations, and handle database migrations.
- User Authentication and Authorization :
Securing your web application is crucial. We'll cover user authentication and authorization using Flask-Login and Flask-Principal. You'll learn how to implement login and registration functionality, password hashing, and role-based access control to ensure that only authorized users can access specific parts of your application.
- Working with APIs :
Flask is excellent for building APIs due to its flexibility and simplicity. We'll guide you through building a RESTful API using Flask-RESTful, allowing you to expose your application's functionality to other applications or front-end frameworks. You'll learn about request parsing, resource routing, authentication, and serialization of data.
- Testing and Debugging :
Testing and debugging are essential aspects of web development. We'll explore different testing strategies using Flask's built-in testing framework and popular libraries like pytest. Additionally, we'll cover techniques for debugging Flask applications, handling errors, and logging.
- Deployment and Production Considerations :
Once your Flask application is ready, you need to deploy it to a production environment. We'll discuss various deployment options, such as using web servers like Nginx or Apache, deploying on cloud platforms like Heroku or AWS, and containerization with Docker. Additionally, we'll cover performance optimization, security considerations, and monitoring techniques.
- Best Practices and Further Resources :
To wrap up the guide, we'll share best practices for Flask development, including code organization, project structure, and documentation. We'll also provide additional resources, such as books, tutorials, and online communities, to help you continue your Flask journey and stay updated with the latest trends.
Conclusion:
Flask offers a lightweight and flexible framework for building web applications with Python. By following this comprehensive guide, you'll gain a solid understanding of Flask's key features and components, empowering you to create robust and scalable web solutions. Remember to practice regularly, experiment with different Flask extensions, and explore real-world examples to enhance your Flask skills. With Flask's simplicity and versatility, you can unleash your creativity and build powerful web applications that meet the needs of your users. Happy Flask coding!
Requests

Sure, here is a detail article on Requests Python:
What is Requests?
Requests is a Python library that makes HTTP requests simpler and more powerful. It is built on top of the urllib3 library, which provides a robust and reliable foundation for making HTTP requests.
Requests provides a number of features that make it a powerful tool for working with HTTP requests, including:
Simple API: The Requests API is simple and easy to use. It provides a high-level interface for making HTTP requests, without requiring you to worry about the low-level details.
Powerful features: Requests provides a number of powerful features for working with HTTP requests, including support for cookies, authentication, and proxies.
Robust library: Requests is a robust library that has been tested and used by thousands of developers. It is reliable and stable, and it is backed by a large and active community of developers.
How to use Requests
To use Requests, you first need to import the library into your Python code. Once you have imported the library, you can use it to make HTTP requests.
The basic syntax for making a HTTP request is as follows:
Code snippet
request = requests.get(url)
where url is the URL of the resource that you want to request.
The request object will contain the response from the HTTP request. You can use the request object to access the response data, status code, and headers.
For example, the following code makes a HTTP request to the Google homepage and prints the response status code:
Code snippet
import requests
url = 'https://www.google.com'
response = requests.get(url)
print(response.status_code)
This code will print the following output:
Code snippet
200
Advanced usage
Requests provides a number of advanced features that can be used for more complex HTTP requests. For example, you can use the requests library to make authenticated requests, use proxies, and handle redirects.
Here are some examples of how to use the advanced features of Requests:
Making authenticated requests: To make an authenticated request, you can use the
requests.authmodule. Therequests.authmodule provides a number of authentication methods, including Basic Authentication, Digest Authentication, and OAuth.Using proxies: To use a proxy, you can use the
requests.proxiesmodule. Therequests.proxiesmodule allows you to specify a proxy server that will be used to make HTTP requests.Handling redirects: To handle redirects, you can use the
requests.adaptersmodule. Therequests.adaptersmodule allows you to specify how Requests should handle redirects.
Conclusion
Requests is a powerful and versatile library for making HTTP requests in Python. It is easy to learn and use, and it provides a wide range of features for working with HTTP requests.
If you are working with HTTP requests, Requests is a great library to consider using. It is powerful, easy to use, flexible, and has a large and active community of users and developers.
Beautiful Soup

Beautiful Soup is a Python library that makes it easy to extract data from HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
Beautiful Soup is a very versatile library that can be used for a wide variety of tasks, including:
Web scraping: Beautiful Soup can be used to extract data from websites. This can be useful for a variety of purposes, such as gathering product information, tracking prices, or getting news headlines.
Data cleaning: Beautiful Soup can be used to clean up HTML and XML files. This can be useful for removing unwanted elements, fixing errors, or making the data more consistent.
Data analysis: Beautiful Soup can be used to analyze data that has been extracted from HTML and XML files. This can be useful for finding trends, identifying patterns, or making predictions.
Beautiful Soup is a powerful and versatile library that can be used for a wide variety of tasks. It is easy to learn and use, and it is supported by a large and active community of users and developers.
Here are some of the benefits of using Beautiful Soup:
Powerful: Beautiful Soup is a very powerful library that can be used to extract data from a wide variety of HTML and XML files.
Easy to use: Beautiful Soup is relatively easy to learn and use, even for beginners.
Flexible: Beautiful Soup is a very flexible library that can be used for a wide variety of tasks, such as web scraping, data cleaning, and data analysis.
Community: Beautiful Soup has a large and active community of users and developers who can provide support and help with troubleshooting.
If you are working with HTML or XML files, Beautiful Soup is a great library to consider using. It is powerful, easy to use, flexible, and has a large and active community of users and developers.
Here are some examples of how Beautiful Soup can be used:
Web scraping: Beautiful Soup can be used to extract data from websites. This can be useful for a variety of purposes, such as gathering product information, tracking prices, or getting news headlines.
Data cleaning: Beautiful Soup can be used to clean up HTML and XML files. This can be useful for removing unwanted elements, fixing errors, or making the data more consistent.
Data analysis: Beautiful Soup can be used to analyze data that has been extracted from HTML and XML files. This can be useful for finding trends, identifying patterns, or making predictions.
Here are some resources for learning more about Beautiful Soup:
Official documentation: The official Beautiful Soup documentation is a great resource for learning about the library.
Tutorials: There are many tutorials available online that can help you get started with Beautiful Soup.
Books: There are several books available that can teach you how to use Beautiful Soup.
Community: The Beautiful Soup community is very active and there are many resources available online for help and support.
SQLAlchemy
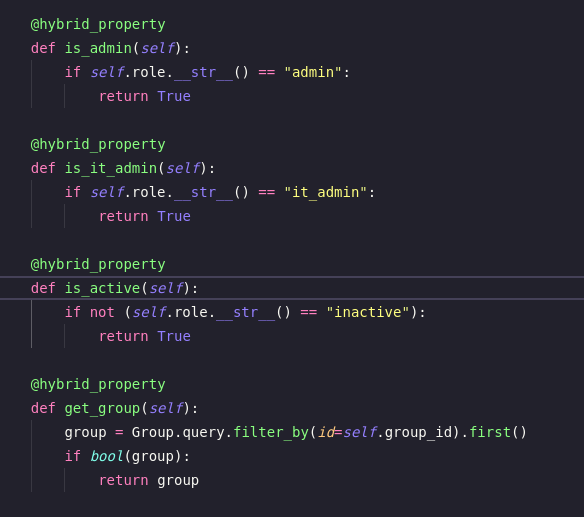
SQLAlchemy is an open-source Python library that provides an Object-Relational Mapper (ORM) and SQL toolkit. It is used to abstract the database layer from the application layer, making it easier to develop applications that use databases.
SQLAlchemy is a powerful and flexible library that can be used with a wide variety of databases, including MySQL, PostgreSQL, Oracle, and SQL Server. It is also compatible with a wide variety of Python versions, including Python 2 and Python 3.
SQLAlchemy provides a number of features that make it a powerful and versatile tool for working with databases, including:
Object-Relational Mapping: SQLAlchemy provides an ORM that allows you to map Python objects to database tables. This makes it easy to work with data in a database, as you can use Python objects to represent the data.
SQL toolkit: SQLAlchemy also provides a SQL toolkit that allows you to write SQL queries and execute them against a database. This gives you the flexibility to use SQL when needed, without having to use the ORM.
Flexibility: SQLAlchemy is a very flexible library that can be used in a variety of ways. It can be used for simple tasks, such as reading and writing data to a database, or for more complex tasks, such as building data warehouses and data lakes.
SQLAlchemy is a great choice for any Python developer who needs to work with databases. It is a powerful, flexible, and easy-to-use library that can be used with a wide variety of databases.
Here are some of the benefits of using SQLAlchemy:
Powerful: SQLAlchemy is a very powerful library that can be used to perform a wide range of database tasks.
Flexible: SQLAlchemy is a very flexible library that can be used to work with a wide variety of databases and data types.
Easy to use: SQLAlchemy is relatively easy to learn and use, even for beginners.
Community: SQLAlchemy has a large and active community of users and developers who can provide support and help with troubleshooting.
If you need to work with databases in Python, SQLAlchemy is a great library to consider using. It is powerful, flexible, easy to use, and has a large and active community of users and developers.
Here are some examples of how SQLAlchemy can be used:
Reading and writing data to a database: SQLAlchemy can be used to read and write data to a database. This can be done using the ORM or the SQL toolkit.
Building data warehouses and data lakes: SQLAlchemy can be used to build data warehouses and data lakes. This can be done by using the ORM to map Python objects to database tables, and then using the SQL toolkit to write SQL queries to load and transform the data.
Performing complex data analysis: SQLAlchemy can be used to perform complex data analysis. This can be done by using the SQL toolkit to write SQL queries to extract data from the database, and then using Python libraries such as Pandas to analyze the data.
Here are some resources for learning more about SQLAlchemy:
Official documentation: The official SQLAlchemy documentation is a great resource for learning about the library.
Tutorials: There are many tutorials available online that can help you get started with SQLAlchemy.
Books: There are several books available that can teach you how to use SQLAlchemy.
Community: The SQLAlchemy community is very active and there are many resources available online for help and support.
Conclusion:
Python's popularity is greatly attributed to its extensive collection of packages and libraries. In this comprehensive guide, we explored just a few of the most popular Python packages across various domains, including data analysis, web development, machine learning, and more. Each package discussed offers unique functionalities and empowers developers to build robust and efficient applications.
Remember, this list is not exhaustive, and the Python package ecosystem is constantly evolving. As you continue your journey as a Python developer, make sure to explore other packages, read documentation, and contribute to the open-source community.
By leveraging the power of these Python packages, you can enhance your development process, accelerate project delivery, and unlock new possibilities in your programming endeavors. So, keep exploring, experimenting, and integrating these packages into your projects to take your Python development skills to the next level.